Azure Container Apps give teams a fast way to run APIs, workers, and background services without managing the full Kubernetes control plane. That convenience is real, but it can create a dangerous illusion: if the deployment feels modern, the security model must already be modern too. In practice, many teams still smuggle secrets into environment variables, CI pipelines, and app settings even when the platform gives them a better option.
The better default is to use managed identities wherever the workload needs to call Azure services. Managed identities do not eliminate every security decision, but they do remove a large class of avoidable secret handling problems. The key is to treat identity design as part of the application architecture, not as a last-minute checkbox after the container already works.
Why Secret-Based Access Keeps Sneaking Back In
Teams usually fall back to secrets because they are easy to understand in the short term. A developer creates a storage key, drops it into a configuration value, tests the app, and moves on. The same pattern then spreads to database connections, Key Vault access, service bus clients, and deployment scripts.
The trouble is that secrets create long-lived trust. They get copied into local machines, build logs, variable groups, and troubleshooting notes. Once that happens, the question is no longer whether the app can reach a service. The real question is how many places now contain reusable credentials that nobody will rotate until something breaks.
Managed Identity Changes the Default Trust Model
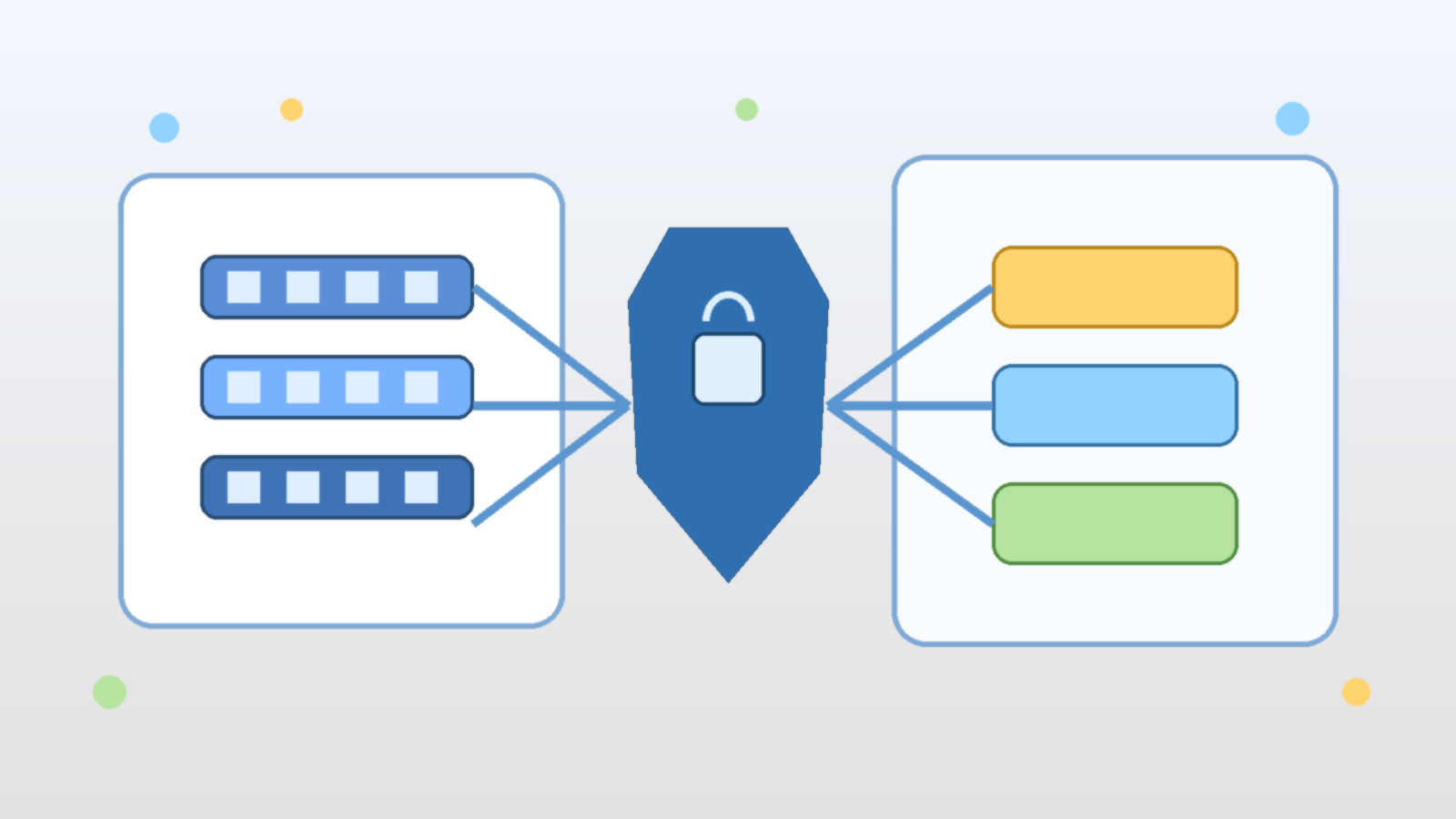
A managed identity lets the Azure platform issue tokens to the workload when it needs to call another Azure resource. That means the application can request access at runtime instead of carrying a static secret around with it. For Azure Container Apps, this is especially useful because the app often needs to reach services such as Key Vault, Storage, Service Bus, Azure SQL, or internal APIs protected through Entra ID.
This shifts the trust model in a healthier direction. Instead of protecting one secret forever, the team protects the identity boundary and the role assignments behind it. Tokens become short-lived, rotation becomes an Azure problem instead of an application problem, and accidental credential sprawl becomes much harder to justify.
Choose System-Assigned or User-Assigned on Purpose
Azure gives you both system-assigned and user-assigned managed identities, and the right choice depends on the workload design. A system-assigned identity is tied directly to one container app. It is simple, clean, and often the right fit when a single application has its own narrow access pattern.
A user-assigned identity makes more sense when several workloads need the same identity boundary, when lifecycle independence matters, or when a platform team wants tighter control over how identity objects are named and reused. The mistake is not choosing one model over the other. The mistake is letting convenience decide without asking whether the identity should follow the app or outlive it.
Grant Access at the Smallest Useful Scope
Managed identity helps most when it is paired with disciplined authorization. If a container app only needs one secret from one vault, it should not receive broad contributor rights on an entire subscription. If it only reads from one queue, it should not be able to manage every messaging namespace in the environment.
That sounds obvious, but broad scope is still where many implementations drift. Teams are under delivery pressure, a role assignment at the resource-group level makes the error disappear, and the temporary fix quietly becomes permanent. Good identity design means pushing back on that shortcut and assigning roles at the narrowest scope that still lets the app function.
Do Not Confuse Key Vault With a Full Security Strategy
Key Vault is useful, but it is not a substitute for proper identity design. Many teams improve from plain-text secrets in source control to secrets pulled from Key Vault at startup, then stop there. That is better than the original pattern, but it can still leave the application holding long-lived credentials it did not need to have in the first place.
If the target Azure service supports Entra-based authentication directly, managed identity is usually the better path. Key Vault still belongs in the architecture for cases where a secret truly must exist, but it should not become an excuse to keep every integration secret-shaped forever.
Plan for Local Development Without Undoing Production Hygiene
One reason secret patterns survive is that developers want a simple local setup. That need is understandable, but the local developer experience should not quietly define the production trust model. The healthier pattern is to let developers authenticate with their own Entra identities locally, while the deployed container app uses its managed identity in Azure.
This keeps environments honest. The code path stays aligned with token-based access, developers retain traceable permissions, and the team avoids inventing an extra pile of shared development secrets just to make the app start up on a laptop.
Observability Matters After the First Successful Token Exchange
Many teams stop thinking about identity as soon as the application can fetch a token and call the target service. That is too early to declare victory. You still need to know which identity the app is using, which resources it can access, how failures surface, and how role changes are reviewed over time.
That is especially important in shared cloud environments where several apps, pipelines, and platform services evolve at once. If identity assignments are not documented and reviewable, a clean managed identity implementation can still drift into a broad trust relationship that nobody intended to create.
Final Takeaway
Managed identities in Azure Container Apps are not just a convenience feature. They are one of the clearest ways to reduce secret sprawl and tighten workload access without slowing teams down. The payoff comes when identity boundaries, scopes, and role assignments are designed deliberately instead of accepted as whatever finally made the deployment succeed.
If your container app still depends on copied connection strings and long-lived credentials, the platform is already giving you a better path. Use it before those secrets become permanent infrastructure baggage.