Agent-to-agent protocols are starting to move from demos into real enterprise architecture conversations. The promise is obvious. Instead of building one giant assistant that tries to do everything, teams can let specialized agents coordinate with each other. One agent may handle research, another may manage approvals, another may retrieve internal documentation, and another may interact with a system of record. In theory, that creates cleaner modularity and better scale. In practice, it can also create a fast-growing trust problem that many teams do not notice until too late.
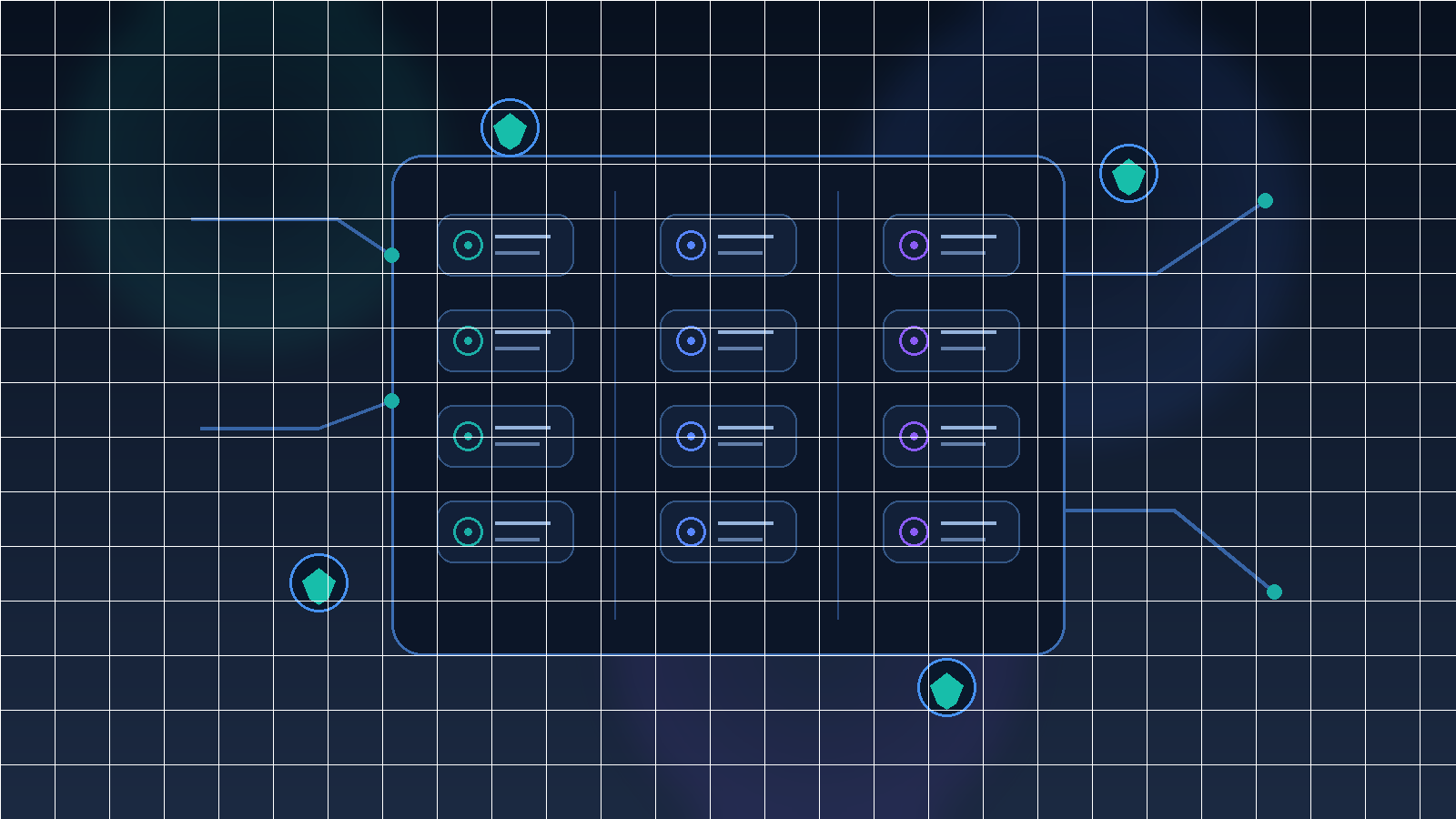
The risk is not simply that one agent makes a bad decision. The deeper issue is that agent-to-agent communication can turn into an invisible trust mesh. As soon as agents can call each other, pass tasks, exchange context, and inherit partial authority, your architecture stops being a single application design question. It becomes an identity, authorization, logging, and containment problem. If you want to pilot agent-to-agent patterns safely, you need to design those controls before the ecosystem gets popular inside your company.
Treat every agent as a workload identity, not a friendly helper
One of the biggest mistakes teams make is treating agents like conversational features instead of software workloads. The interface may feel friendly, but the operational reality is closer to service-to-service communication. Each agent can receive requests, call tools, reach data sources, and trigger actions. That means each one should be modeled as a distinct identity with a defined purpose, clear scope, and explicit ownership.
If two agents share the same credentials, the same API key, or the same broad access token, you lose the ability to say which one did what. You also make containment harder when one workflow behaves badly. Give each agent its own identity, bind it to specific resources, and document which upstream agents are allowed to delegate work to it. That sounds strict, but it is much easier than untangling a cluster of semi-trusted automations after several teams have started wiring them together.
Do not let delegation quietly become privilege expansion
Agent-to-agent designs often look clean on a whiteboard because delegation is framed as a simple handoff. In reality, delegation can hide privilege expansion. An orchestration agent with broad visibility may call a domain agent that has write access to a sensitive system. A support agent may ask an infrastructure agent to perform a task that the original requester should never have been able to trigger indirectly. If those boundaries are not explicit, the protocol turns into an accidental privilege broker.
A safer pattern is to evaluate every handoff through two questions. First, what authority is the calling agent allowed to delegate? Second, what authority is the receiving agent willing to accept for this specific request? The second question matters because the receiver should not assume that every incoming request is automatically valid. It should verify the identity of the caller, the type of task being requested, and the policy rules around that relationship. Delegation should narrow and clarify authority, not blur it.
Map trust relationships before you scale the ecosystem
Most teams are comfortable drawing application dependency diagrams. Fewer teams draw trust relationship maps for agents. That omission becomes costly once multiple business units start piloting their own agent stacks. Without a trust map, you cannot easily answer basic governance questions. Which agents can invoke which other agents? Which ones are allowed to pass user context? Which ones may request tool use, and under what conditions? Where does human approval interrupt the flow?
Before you expand an agent-to-agent pilot, create a lightweight trust registry. It does not need to be fancy. It does need to list the participating agents, their owners, the systems they can reach, the types of requests they can accept, and the allowed caller relationships. This becomes the backbone for reviews, audits, and incident response. Without it, agent connectivity spreads through convenience rather than design, and convenience is a terrible security model.
Separate context sharing from tool authority
Another common failure mode is assuming that because one agent can share context with another, it should also be able to trigger the second agent’s tools. Those are different trust decisions. Context sharing may be limited to summarization, classification, or planning. Tool authority may involve ticket changes, infrastructure updates, customer record access, or outbound communication. Conflating the two leads to more power than the workflow actually needs.
Design the protocol so context exchange is scoped independently from action rights. For example, a planning agent may be allowed to send sanitized task context to a deployment agent, but only a human-approved workflow token should allow the deployment step itself. This separation keeps collaboration useful while preventing one loosely governed agent from becoming a shortcut to operational control. It also makes audits more understandable because reviewers can distinguish informational flows from action-bearing flows.
Build logging that preserves the delegation chain
When something goes wrong in an agent ecosystem, a generic activity log is not enough. You need to reconstruct the delegation chain. That means recording the original requester when applicable, the calling agent, the receiving agent, the policy decision taken at each step, the tools invoked, and the final outcome. If your logging only shows that Agent C called a database or submitted a change, you are missing the chain of trust that explains why that action happened.
Good logging for agent-to-agent systems should answer four things quickly: who initiated the workflow, which agents participated, which policies allowed or blocked each hop, and what data or tools were touched along the way. That level of traceability is not just for incident response. It also helps operations teams separate a protocol design flaw from a prompt issue, a mis-scoped permission, or a broken integration. Without chain-aware logging, every investigation gets slower and more speculative.
Put hard stops around high-risk actions
Agent-to-agent workflows are most useful when they reduce routine coordination work. They are most dangerous when they create a smooth path to high-impact actions without a meaningful stop. A pilot should define clear categories of actions that require stronger controls, such as production changes, financial commitments, permission grants, sensitive data exports, or outbound communications that represent the company.
For those cases, use approval boundaries that are hard to bypass through delegation tricks. A downstream agent should not be able to claim that an upstream agent already validated the request unless that approval is explicit, scoped, and auditable. Human review is not required for every low-risk step, but it should appear at the points where business, security, or reputational impact becomes material. A pilot that proves useful while preserving these stops is much more likely to survive real governance review.
Start with a small protocol neighborhood
It is tempting to let every promising agent participate once a protocol seems to work. Resist that urge. Early pilots should operate inside a small protocol neighborhood with intentionally limited participants. Pick a narrow use case, define two or three agent roles, control the allowed relationships, and keep the reachable systems modest. This gives the team room to test reliability, logging, and policy behavior without creating a sprawling network of assumptions.
That smaller scope also makes governance conversations better. Instead of debating abstract future risk, the team can review one contained design and ask whether the trust model is clear, whether the telemetry is good enough, and whether the escalation path makes sense. Expansion should happen only after those basics are working. The protocol is not the product. The operating model around it is what determines whether the product remains manageable.
A practical minimum standard for enterprise pilots
If you want a realistic starting point for piloting agent-to-agent patterns in an enterprise setting, the minimum standard should include the following controls:
- Distinct identities for each agent, with clear owners and documented purpose.
- Explicit allowlists for which agents may call which other agents.
- Policy checks on delegation, not just on final tool execution.
- Separate controls for context sharing versus action authority.
- Chain-aware logging that records each hop, policy decision, and resulting action.
- Human approval boundaries for high-risk actions and sensitive data movement.
- A maintained trust registry for participating agents, reachable systems, and approved relationships.
That is not excessive overhead. It is the minimum structure needed to keep a protocol pilot from turning into a distributed trust problem that nobody fully owns.
The real design challenge is trust, not messaging
Agent-to-agent protocols will keep improving, and that is useful. Better interoperability can absolutely reduce duplicated tooling and help organizations compose specialized capabilities more cleanly. But the hard part is not getting agents to talk. The hard part is deciding what they are allowed to mean to each other. The trust model matters more than the message format.
Teams that recognize that early will pilot these patterns with far fewer surprises. They will know which relationships are approved, which actions need hard stops, and how to explain an incident when something misfires. That is the difference between a protocol experiment that stays governable and one that quietly grows into a cross-team automation mesh no one can confidently defend.