Most enterprise teams understand the need to separate development, test, and production environments for ordinary software. The confusion starts when AI enters the stack. Some teams treat models, prompts, connectors, and evaluation data as if they can float across environments with only light labeling. That usually works until a prototype prompt leaks into production, a test connector touches live content, or a platform team realizes that its audit trail cannot clearly explain which behavior belonged to which stage.
Environment separation for AI is not only about keeping systems neat. It is about preserving trust in how model-backed behavior is built, reviewed, and released. The goal is not to create three times as much bureaucracy. The goal is to keep experimentation flexible while making production behavior boring in the best possible way.
Separate More Than the Endpoint
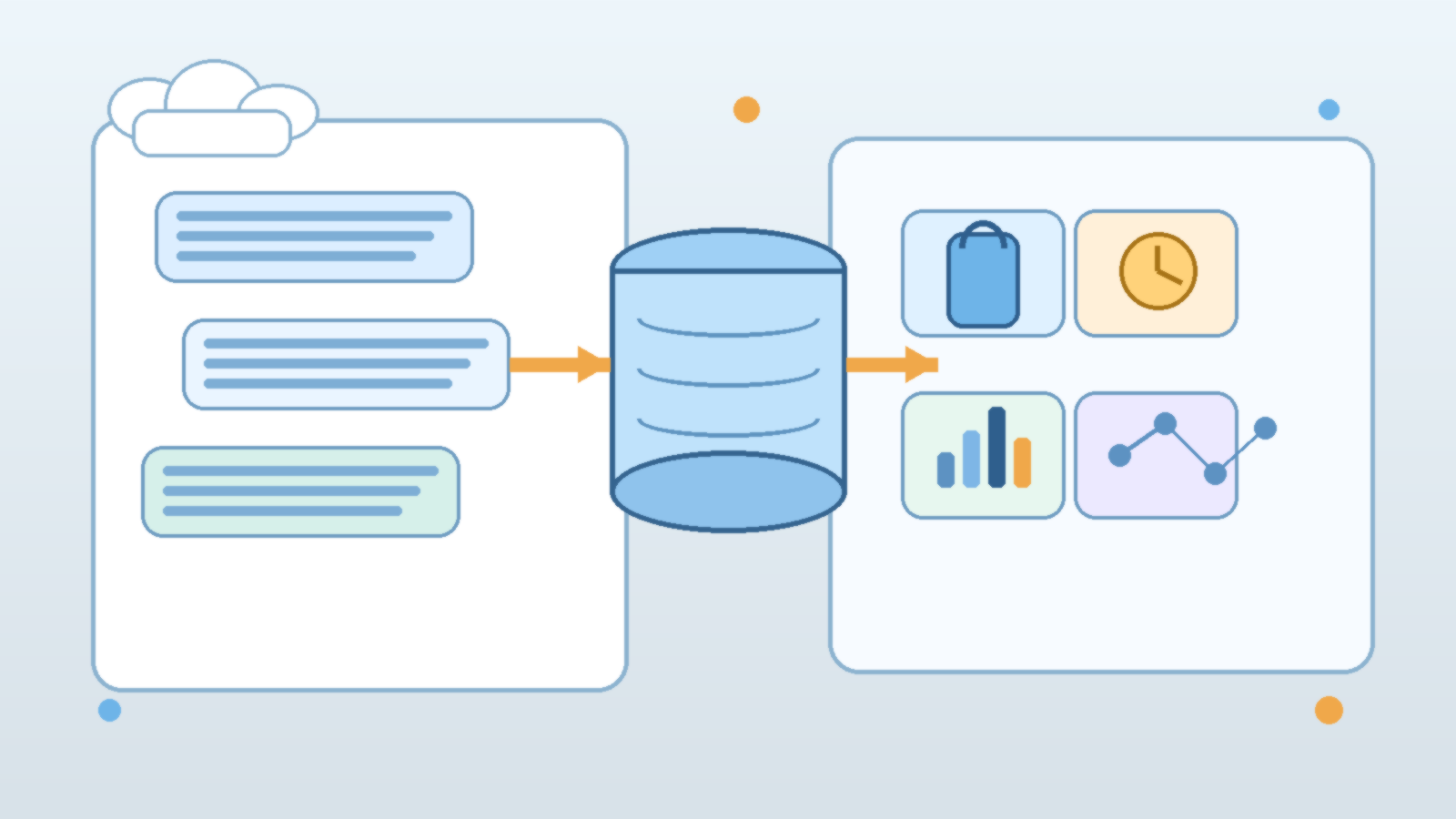
A common mistake is to say an AI platform has proper environment separation because development uses one deployment name and production uses another. That is a start, but it is not enough. Strong separation usually includes the model deployment, prompt configuration, tool permissions, retrieval sources, secrets, logging destinations, and approval path. If only the endpoint changes while everything else stays shared, the system still has plenty of room for cross-environment confusion.
This matters because AI behavior is assembled from several moving parts. The model is only one layer. A team may keep production on a stable deployment while still allowing a development prompt template, a loose retrieval connector, or a broad service principal to shape what happens in practice. Clean boundaries come from the full path, not from one variable in an app settings file.
Let Development Move Fast, but Keep Production Boring
Development environments should support quick prompt iteration, evaluation experiments, and integration changes. That freedom is useful because AI systems often need more tuning cycles than conventional application features. The problem appears when teams quietly import that experimentation style into production. A platform becomes harder to govern when the live environment is treated like an always-open workshop.
The healthier pattern is to make development intentionally flexible and production intentionally predictable. Developers can explore different prompt structures, tool choices, and ranking logic in lower environments, but the release path into production should narrow sharply. A production change should look like a reviewed release, not a late-night tweak that happened to improve a metric.
Use Test Environments to Validate Operational Behavior, Not Just Output Quality
Many teams use test environments only to see whether the answer looks right. That is too small a role for a critical stage. Test should also validate the operational behavior around the model: access control, logging, rate limits, fallback behavior, content filtering, connector scope, and cost visibility. If those controls are not exercised before production, the organization is not really testing the system it plans to operate.
That operational focus is especially important when several internal teams share the same AI platform. A production incident rarely begins with one wrong sentence on a screen. It usually begins with a control that behaved differently than expected under real load or with real data. Test environments exist to catch those mismatches while the blast radius is still small.
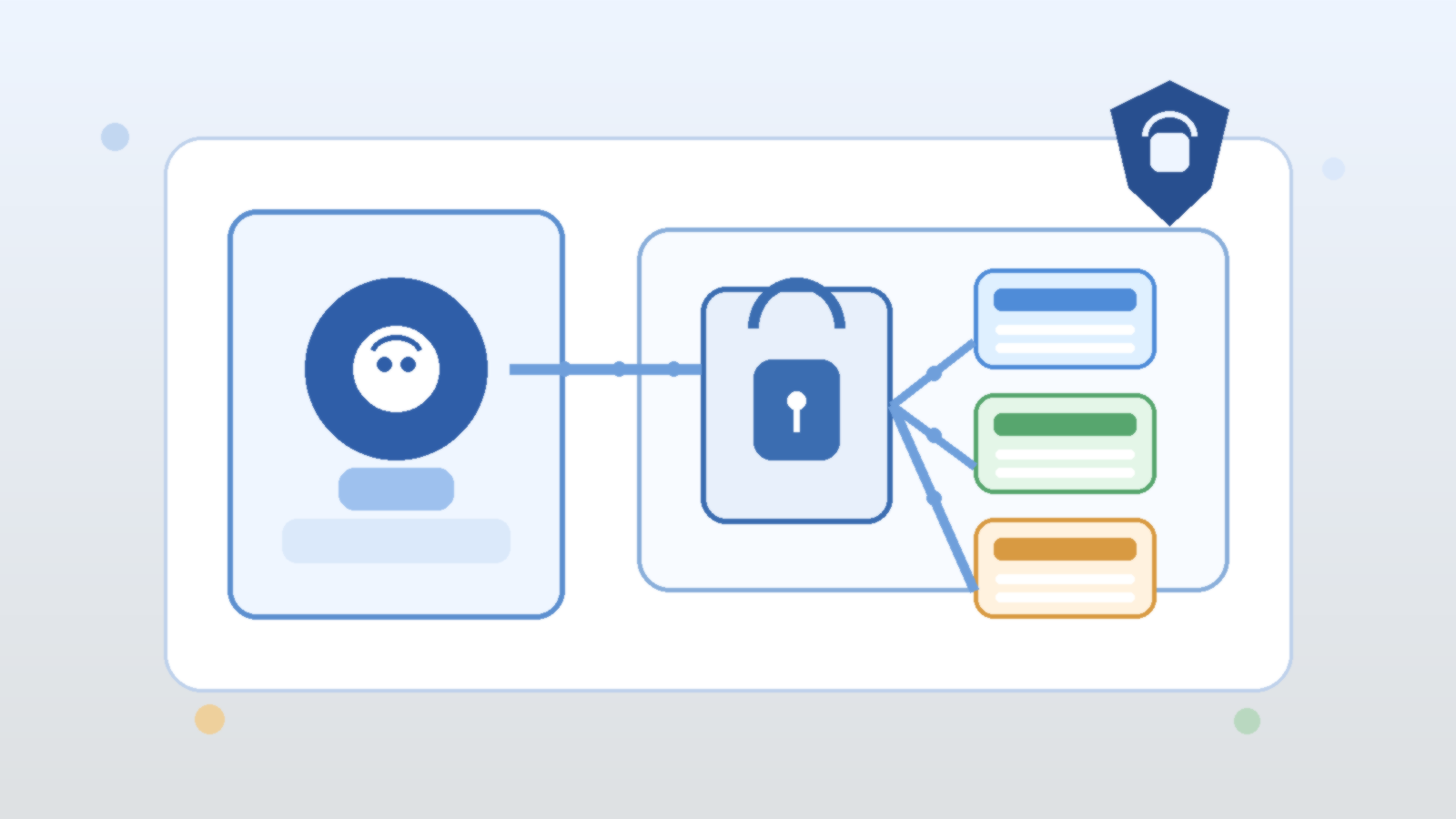
Keep Identity and Secret Boundaries Aligned to the Environment
Environment separation breaks down quickly when identities are shared. If development, test, and production all rely on the same broad credential or connector identity, the labels may differ while the risk stays the same. Separate managed identities, narrower role assignments, and environment-specific secret scopes make it much easier to understand what each stage can actually touch.
This is one of those areas where small shortcuts create large future confusion. Shared identities make early setup easier, but they also blur ownership during incident response and audit review. When a risky retrieval or tool call appears in logs, teams should be able to tell immediately which environment made it and what permissions it was supposed to have.
Treat Prompt and Retrieval Changes Like Release Artifacts
AI teams sometimes version code carefully while leaving prompts and retrieval settings in a loose operational gray zone. That gap is dangerous because those assets often shape behavior more directly than the surrounding application code. Prompt templates, grounding strategies, ranking weights, and safety instructions should move through environments with the same basic discipline as application releases.
That does not require heavyweight ceremony. It does require traceability. Teams should know which prompt set is active in each environment, what changed between versions, and who approved the production promotion. The point is not to slow learning. The point is to prevent a platform from becoming impossible to explain after six months of rapid iteration.
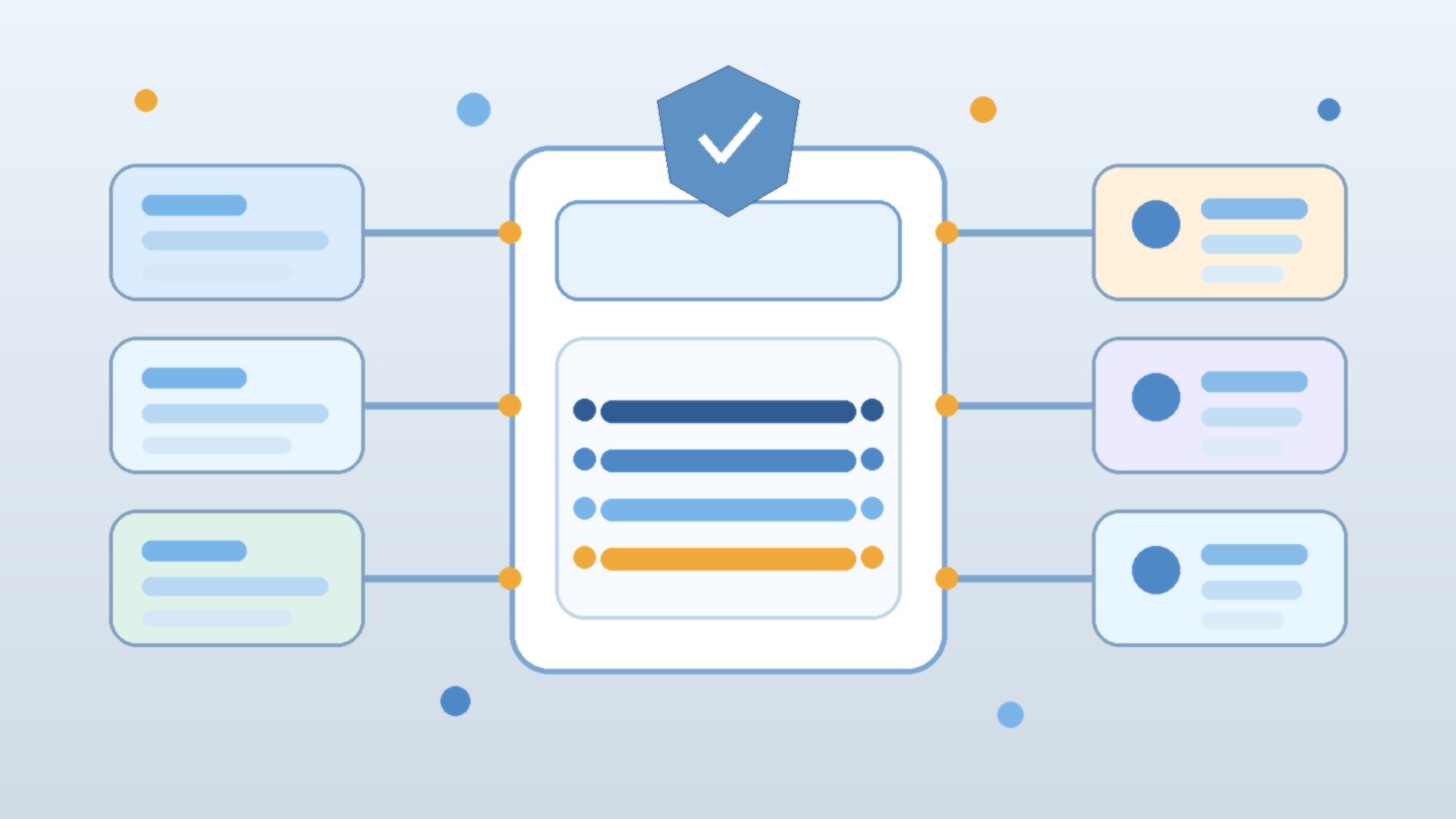
Avoid Multiplying Governance by Standardizing the Control Pattern
Some leaders resist stronger separation because they assume it means three independent stacks of policy and paperwork. That is the wrong design target. Good platform teams standardize the control pattern across environments while changing the risk posture at each stage. The same policy families can exist everywhere, but production should have tighter defaults, narrower permissions, stronger approvals, and more durable logging.
That approach reduces overhead because engineers learn one operating model instead of three unrelated ones. It also improves governance quality. Reviewers can compare development, test, and production using the same conceptual map: identity, connector scope, prompt version, model deployment, approval gate, telemetry, and rollback path.
Define Promotion Rules Before the First High-Pressure Launch
The worst time to invent environment rules is during a rushed release. Promotion criteria should exist before the platform becomes politically important. A practical checklist might require evaluation results above a defined threshold, explicit review of tool permissions, confirmation of logging coverage, connector scope verification, and a documented rollback plan. Those are not glamorous tasks, but they prevent fragile launches.
Production AI should feel intentionally promoted, not accidentally arrived at. If a team cannot explain why a model behavior is ready for production, it probably is not. The discipline may look fussy during calm weeks, but it becomes invaluable during audits, incidents, and leadership questions about how the system is actually controlled.
Final Takeaway
Separating dev, test, and prod in Azure AI is not about pretending AI needs a totally new operating philosophy. It is about applying familiar environment discipline to a stack that includes models, prompts, connectors, identities, and evaluation flows. Teams that separate those elements cleanly usually move faster over time because production becomes easier to trust and easier to debug.
Teams that skip the discipline often discover the same lesson the hard way: a shared AI platform becomes expensive and politically fragile when nobody can prove which environment owned which behavior. Strong separation keeps experimentation useful and governance manageable at the same time.